
If a business makes money on the Internet, it is always — in one way or another — collecting and analyzing data, for example, types of products that users look at or skip. Or who is watching a video together, with the information about the type of device and the time of day. Such data is needed to understand how to develop one’s product.
The more data there is, the more difficult it is to process. Because of this, high-load systems become necessary. Using an example from our development team, we’ll tell you how we design such solutions. In April, our system processed 2.4 billion impressions and 408 million clicks with no failures.
The business task is to increase conversion from content display.
One of the ways to make money for an online business is to manage content so that users take targeted actions as often as possible. Content in this case is a general designation. It can mean:
- videos
- news
- goods or services
The target action also depends on the business. In one case it could be a review of a certain number of videos. In another — it might be subscription to trial lessons from the mailing list.
Content management requires data on how the user works with the content. Maybe one skips the products cards with the highest margins for the company, or studies them, but doesn’t put them in the basket. All this is needed to understand how and what to show to the user.
A block of data gives us little information by itself. It needs to be saved and analyzed. For example, you can:
- collect statistical reports according to data segments and metrics
- compare these metrics for different periods
- group data by categories: countries, cities, device types, or time of day
Without such details, it’s difficult to determine why some content is not working as planned, and what to do to solve the problem.
When there is not a lot of data, it can be processed manually, or with the help of simple programs. But with the growth of the user database, the amount of data also increases, so it becomes no longer possible to process, let’s say, a billion pieces of data in this way.
To process a larger load, data collection and analysis systems are being designed. The main requirement for them is to withstand high loads.
OrbitSoft Experience: how data collection and analysis system operates
We have experience in running systems that handle such high loads. Therefore, using the example of one of our projects, we will show our approach to the development.
About the Project. Every day the ad network registers events: bids that users place, ad impressions, ad clicks. In order for analysts to work with data, it needs to be brought into a readable format — processed and loaded into a program with a clear interface.
System load. In April 2021 the ad network system processed:
- 2,4 billion impressions
- 408 million clicks
- 1240 conversions
Analysis. To design the system, we looked at the type and amount of data, the predictable load increase, the results to be obtained, and budget and resource limitation. After that, the development began.
Algorithm of data collection and analysis in the ad network
-
Clicks, bids, impressions
-
File creation and compression
-
Statistics calculation
-
Recording of the results
-
Data is transferred to MySQL
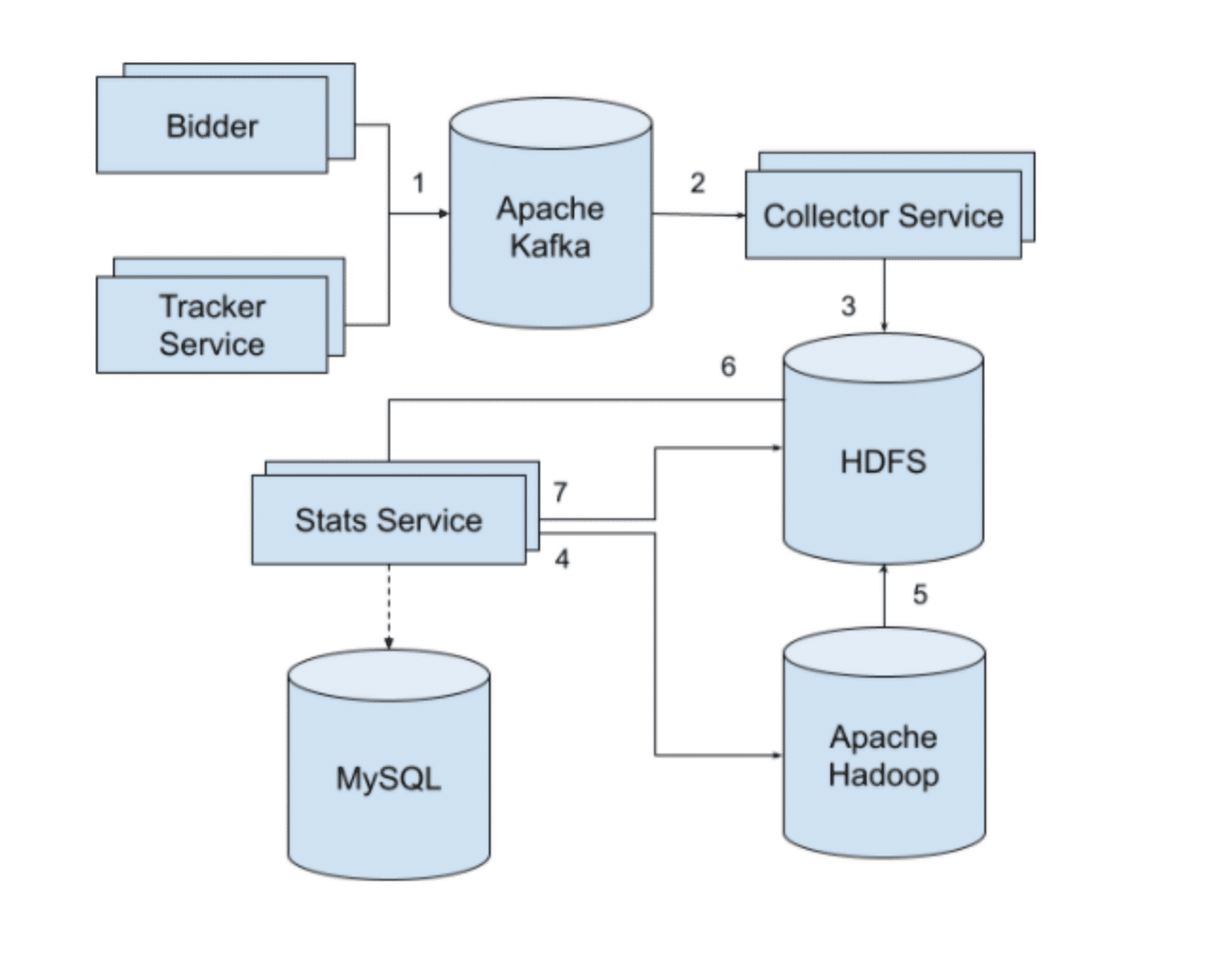
System operation scheme:
- The advertising platform registers events with Apache Kafka.
- Collector Service monitors the queue of events in Apache Kafka, adds more data to event information, and saves event information to .csv files.
- After completing this process, Collector Service compresses it and loads this file into HDFS, in a special directory for input data.
- Every 5 minutes Stats Service checks for new raw files in the HDSF input directory.
- Apache Hadoop calculates statistics based on input data and writes the results to files in a special directory on HDFS.
- Stats Server picks up the results of calculating statistics from HDFS and exports the data to MySQL.
- Stats Server moves the processed input files to an archive located also on HDFS. Files are grouped by day — this is necessary so that statistics can be recalculated for a certain period if there were any errors in the scripts.
Results. All components of the architecture are horizontally scalable and provide fault tolerance.
| Component | What it provides |
| Apache Kafka Distributed Message Broker. | Processes up to several hundred thousand events per second. Messages get through even if one of the servers goes down Adapts to the growth of the load: it’s easy to add new servers |
| Collector Service daemon in Go | Processes tens of thousands of messages per second Adapts to the growth of the load: it can run several copies of the service in parallel and distribute work between them |
| Hadoop Distributed File System | Stores data securely Gives the data that was asked for Records what was sent to the system. Replicated blocks across data nodes will not lose data |
| Stats Server daemon in Java | Fast computation speed with Map Reduce computation model: the data array is divided into parts; each part is processed simultaneously and gathered in to one |
Experts will answer your questions
OrbitSoft experts answer questions from developers, business owners and managers. Ask about everything, even if you are just wondering.
If you want us to analyze your situation or share our experience, write to anna.mandrikina@orbitsoft.com.
