
In brief
-
01
Customer
An advertising platform that works with RTB auctions
-
02
Task
Develop an AI model that wins auctions to place ads on sites with the right target audience
-
03
Solution
- Processed the provided training data, defined metrics for model building
- Selected, trained, and tested suitable machine learning models
-
04
Result
- Determined that the data collected by the customer was not suitable for training
- Stopped at the research stage without spending the customer’s money on the full development and implementation cycle
- Suggested that the customer rebuild the data collection system to make the model predictions effective
Companies collect a huge amount of data: about users, the effectiveness of advertising, the performance of services, etc. Modern tools, such as artificial intelligence, help to analyze, interpret, and turn this data to the company’s advantage.
For example, we developed an algorithm for predicting click-through rates for a large advertising platform that earns money from ad placements. The platform collects information on the reaction of users of various sites to ads: clicked, watched to the end, ignored, and closed without watching. We created an algorithm that predicts on which site the effectiveness of advertising will be higher. As a result, the CTR of the platform’s clients has increased by an average of 20%, and with it, revenue the company.
However, it’s not always possible to make effective predictions using artificial intelligence. To develop and train an algorithm, you need a sufficient amount of high-quality training data. If its collection is not organized correctly, the result will be unreliable. Using a case study from another advertising company, we describe how data quality affects the results of AI algorithm development, and why we need preliminary research.
Customer: large advertising platform
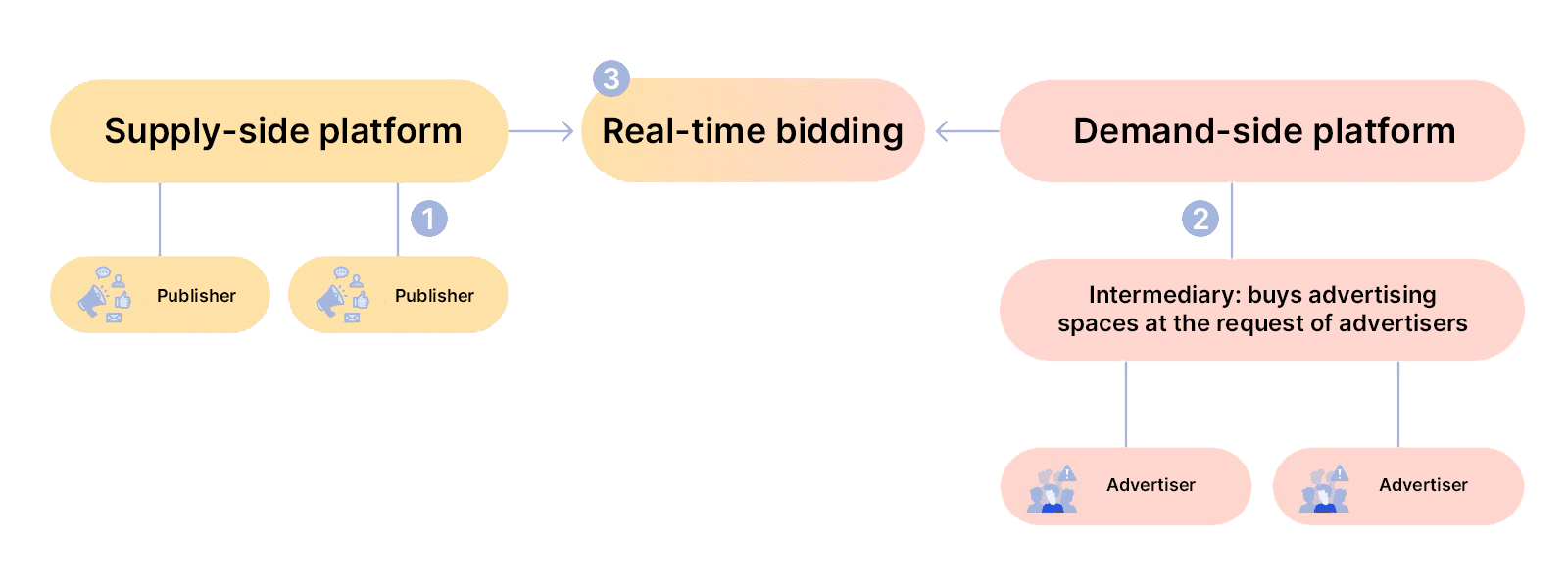
An Israeli company works with real-time bidding (RTB): it helps advertisers select sites with the right target audience, and places ads on them at the lowest cost. Real-time bidding technology allows for the purchase of advertising space, and places ads in real time.
How does RTB work:
1. Websites with high incoming traffic (publishers) sell advertising space. For a fee, they show banners, videos, pop-ups, and other ads to their visitors. To let advertisers see who is on the site, publishers collect data from visitors: location, device, login page, etc. This data is sent to the SSP-system (supply-side platform). Much advertising is generated.
2. Advertisers search for sites with their target audience. They send a request to the DSP (demand-side platform) with a portrait of the audience they want, and a quote for the price at which they want to buy ad space.
3. The SSP-system conducts the real-time bidding and chooses the winners: the ones who offered the highest price will place their ads on the publisher’s site.
Objective: to increase the number of auctions won
To win auctions to place ads, a price must be offered that will «outbid» other bidders, and be acceptable to the platform’s clients, the advertisers. But it’s not enough just to place ads: the platform will only be rewarded if users click on them. So, platforms still must be chosen with an interested audience.
The company was tasked with developing an artificial intelligence model that selects sites with the right audience, and predicts what kind of price offer will win auctions on them.
Solution: create a price prediction model
The customer turned to OrbitSoft. They wanted to implement one of our developments into their platform code, which had already shown successful results in similar cases: the Predictor algorithm. It’s a machine learning (ML) model that uses artificial intelligence to predict the probability of events. It’s based on the ability to find patterns between events, draw conclusions, and apply them to predictions.
To teach artificial intelligence to select auctions with the right audience and win them, a machine learning model needs to be created and trained on a lot of data about audience behavior, and on auctions that have already been won. The sequence of steps is as follows:
- Collect training data: information about auction bids, wins, impressions of purchased ads, and users who click on these ads. Establish links between the metrics.
- Create a mathematical model and load data into it.
- The model builds a dependency function and finds crossover points, the points where the values of variables coincide: bid, win, conversion, and metrics of users. For example, for users from country A to click on an advertisement, it should be placed on site B by making a B bid on the auction.
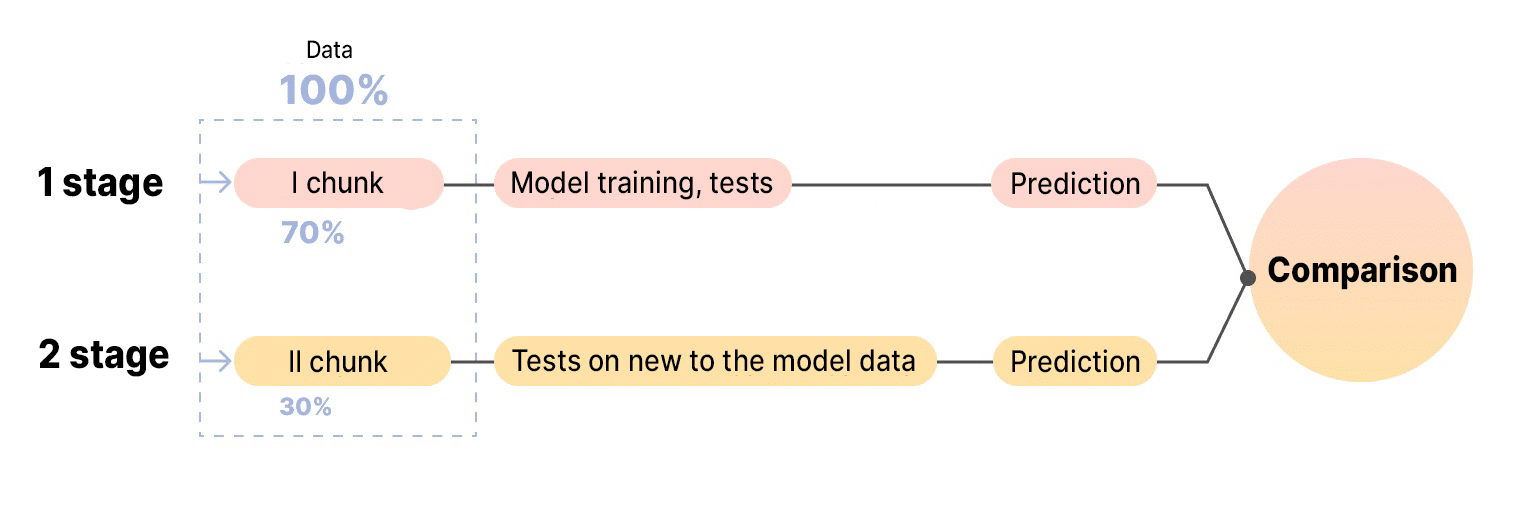
- Test the model: load the next batch of data into it and check the probability of the event it predicts. Part of the test is performed on new data that the machine has not before. This will show whether the results of the training tests coincide with real results.
Testing takes place many times. This helps the model to learn by itself. Regularities that give an unfulfilled prediction are deleted from the system. We leave the data on successful predictions. We continue to test the algorithm until it learns to make realistic forecasts.

Started to develop an ML model and faced the problem of poor data
Researched the data and determined the metrics on which we will build the model
The customer’s platform processes 500 billion unique events per month, enough for a machine learning model. However, analysis showed that there was a lot of repetition and «garbage» in the data. When the database was cleaned up, 47 million rows remained.
We categorized the data and counted the number of events:
- Auctions held: 22,746,723
- Auctions won: 5,390,678
- Ad impressions: 5,389,276
- Ad clicks: 228,977
Selected, trained and tested models
Given the found constraints, we selected and tested 28 models for prediction training, e.g., linear regression, CCPM, FNN, and PNN. We also took multitasking models: shared bottom, ESMM, MMOE and others.
Models were trained on platform data for 2 months. They were divided into portions at a ratio of 80/20 or 70/30: the larger portion was used to train the model, and the smaller one to predict the probability of the dynamic price per thousand impressions, clicks, and conversions. Each result was entered into a table, compared, and analyzed.
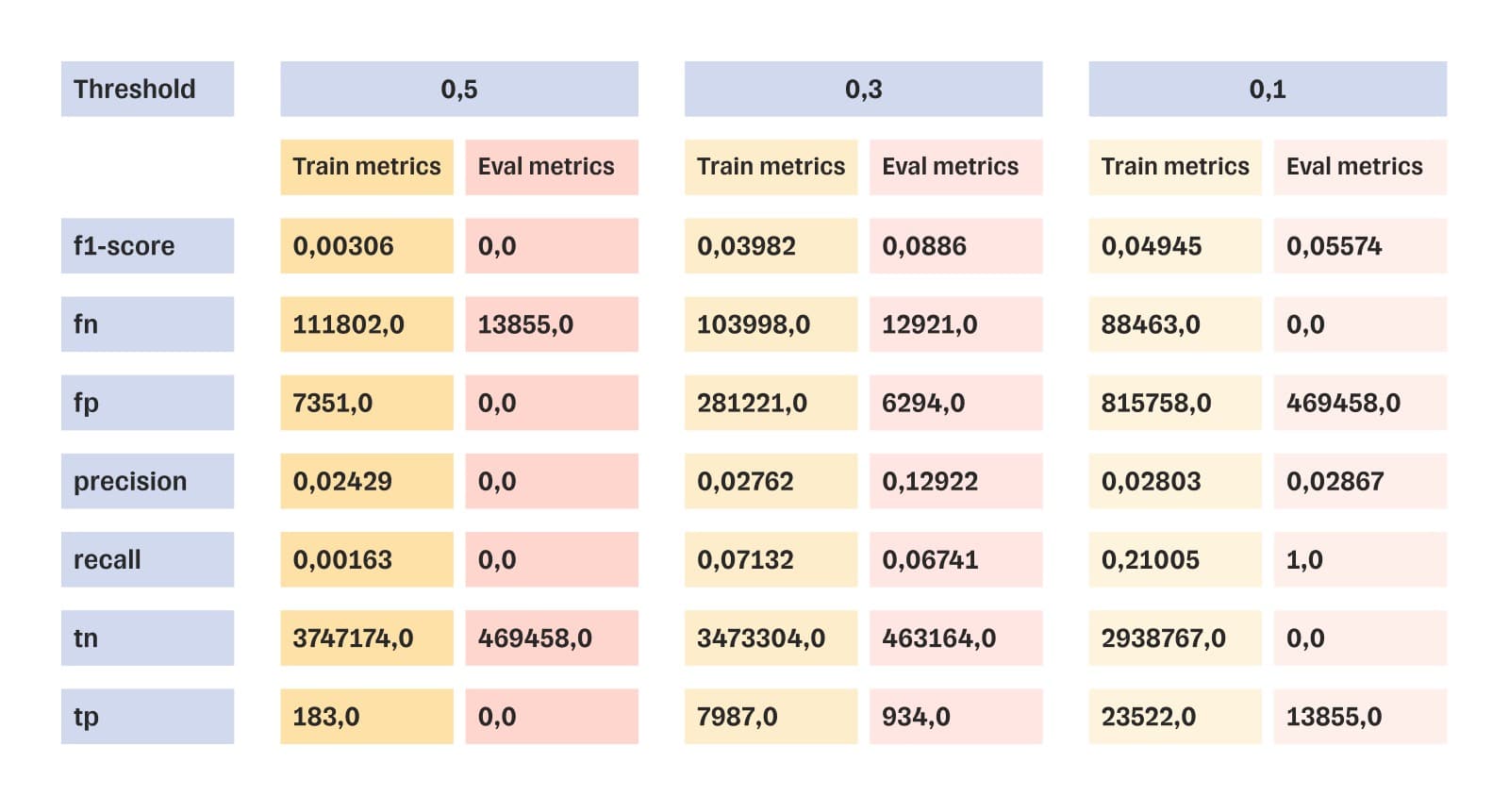
Test results of one of 28 models — linear regression
Evaluated the results of machine learning
Out of 28 trained models, we selected 5. The most effective one was tested even more. To understand whether a model is suitable for the task, we correlated its f1-score with the threshold value of the metric.
If the f1-score reaches the threshold value of 0.4, the model will give a correct prediction with a probability of 40%. If the coefficient is below the threshold value, then the model will not give a meaningful result. The best f1-score for the most productive model was 0.19. This is half the threshold value. This means that this model should not be implemented: the forecasts will be unreliable.
Result: stopped at the research stage, without spending money on the full cycle of development and implementation
After testing all suitable machine learning algorithms, we determined that the data collected by the customer was not suitable for training. None of the trained models produced reliable predictions.
We stopped at the preliminary research stage and didn’t move on to implementing the predictor algorithm in the code of the advertising platform. This way the customer tested his idea and saved money by not investing in an algorithm that didn’t work.
We suggested that the customer rebuild the data collection system. We will determine the categories and how much data to collect, and then go back to implementing the model. In this case it will be trained faster, and predictions will be effective.
