
Коротко о проекте
-
01
Заказчик
Рекламная платформа, которая работает с RTB-аукционами
-
02
Задача
Разработать AI-модель, которая выигрывает аукционы на размещение рекламы на площадках с нужной ЦА
-
03
Решение
- Обработали предоставленные тренировочные данные, определили метрики для построения модели
- Выбрали, натренировали и протестировали подходящие модели машинного обучения
-
04
Результат
- Определили, что собранные заказчиком данные не подходят для тренировки
- Остановились на этапе исследования, не потратив деньги заказчика на полный цикл разработки и внедрения
- Предложили заказчику пересобрать систему сбора данных, чтобы прогнозы модели стали результативными
Компании собирают огромное количество данных: о пользователях, эффективности рекламы, работе сервисов. Современные инструменты, такие как искусственный интеллект, помогают эти данные анализировать, интерпретировать и обращать на пользу компании.
Так, для крупной рекламной платформы, которая зарабатывает на размещении рекламы, мы разработали алгоритм предсказания кликабельности. Платформа собирает информацию о реакции пользователей различных сайтов на рекламу: кликнул, досмотрел до конца, проигнорировал, закрыл не досмотрев. Мы создали алгоритм, который предсказывает, на каком сайте эффективность рекламы конкретного рекламодателя будет выше. В результате CTR клиентов платформы увеличился в среднем на 20%, а с ним и доход самой компании.
Однако эффективно строить прогнозы с помощью искусственного интеллекта получается не всегда. Чтобы разработать и обучить алгоритм, нужны качественные тренировочные данные в достаточном количестве. Если их сбор организован неправильно, результат получится недостоверным.
На примере кейса другой рекламной компании рассказываем, как качество данных влияет на результаты разработки AI-алгоритма и зачем нужны предварительные исследования.
Заказчик: крупная рекламная платформа
Израильская компания работает с RTB-аукционами: помогает рекламодателям подбирать сайты с нужной целевой аудиторией и размещать на них рекламу по наименьшей стоимости. Технология real time bidding позволяет покупать рекламные места и размещать рекламу в режиме реального времени.
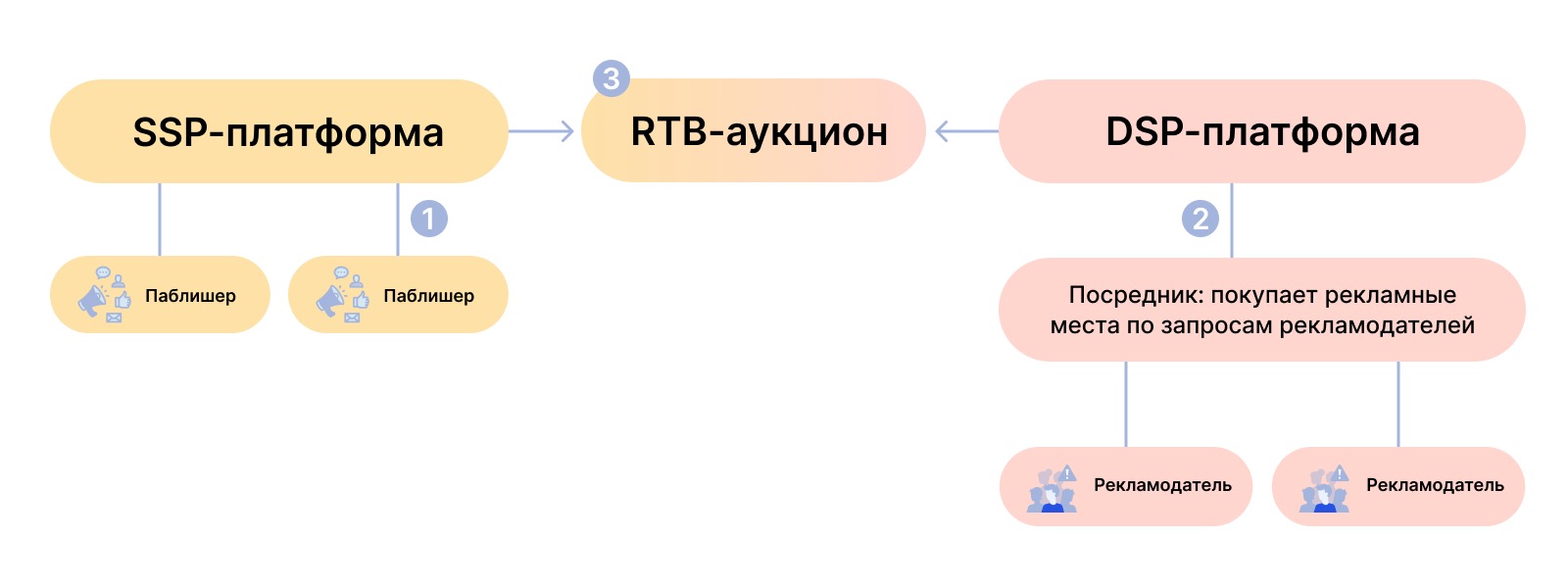
Как работает RTB-аукцион:
1. Сайты с большим входящим трафиком (publisher) продают места для размещения рекламы. За вознаграждение они показывают посетителям своих сайтов баннеры, видео, поп-апы и другую рекламу. Чтобы рекламодатели видели, какая аудитория обитает на сайте, паблишеры собирают данные посетителей: местоположение, устройство, страница входа. Эти данные отправляют в SSP-систему (sell side platform). Формируется лот на размещение рекламы.
2. Рекламодатели ищут сайты со своей целевой аудиторией. Они отправляют запрос в DSP-систему (demand side platform) с портретом нужной им аудитории и предложением о цене, по которой они хотят купить рекламное место.
3. SSP-система проводит RTB-аукцион и выбирает победителей: кто предложил наибольшую цену, тот разместит свою рекламу на сайте паблишера.
Задача: увеличить количество выигранных аукционов
Чтобы выигрывать аукционы на размещение рекламы, нужно предлагать цену, которая «перебьет» заявки других участников и будет приемлема для клиентов платформы — рекламодателей. Но рекламу недостаточно просто разместить: платформа получит вознаграждение, только если пользователи на нее кликнут. Значит, нужно еще выбирать площадки с заинтересованной аудиторией.
Перед компанией стояла задача разработать модель искусственного интеллекта, которая выбирает площадки с нужной аудиторией и предсказывает, с каким ценовым предложением получится выиграть на них аукционы.
Решение: создать модель прогнозирования цены
Заказчик обратился в OrbitSoft. Он хотел внедрить в код своей платформы одну из наших разработок, которая уже показывала успешные результаты в похожих кейсах — алгоритм Predictor. Это модель машинного обучения (ML), которая с помощью искусственного интеллекта предсказывает вероятность событий. В основе ее работы лежит способность находить закономерности между событиями, делать выводы и применять их в составлении прогнозов.
Чтобы научить искусственный интеллект выбирать аукционы с нужной аудиторией и выигрывать их, нужно создать модель машинного обучения и натренировать ее на большом количестве данных о поведении аудитории и об уже выигранных аукционах. Последовательность действий такая:
- Собираем тренировочные данные — информацию об аукционных ставках, выигрышах, показах купленной рекламы, пользователях, которые на эту рекламу кликают. Устанавливаем связи между метриками.
- Создаем математическую модель и загружаем в нее данные.
- Модель строит функцию зависимости и находит точки пересечения — моменты, где совпадают значения переменных: ставка, выигрыш, конверсия, метрики пользователей. Например, чтобы пользователи из страны, А кликали на рекламу, ее нужно разместить на сайте Б, сделав на аукционе ставку В.
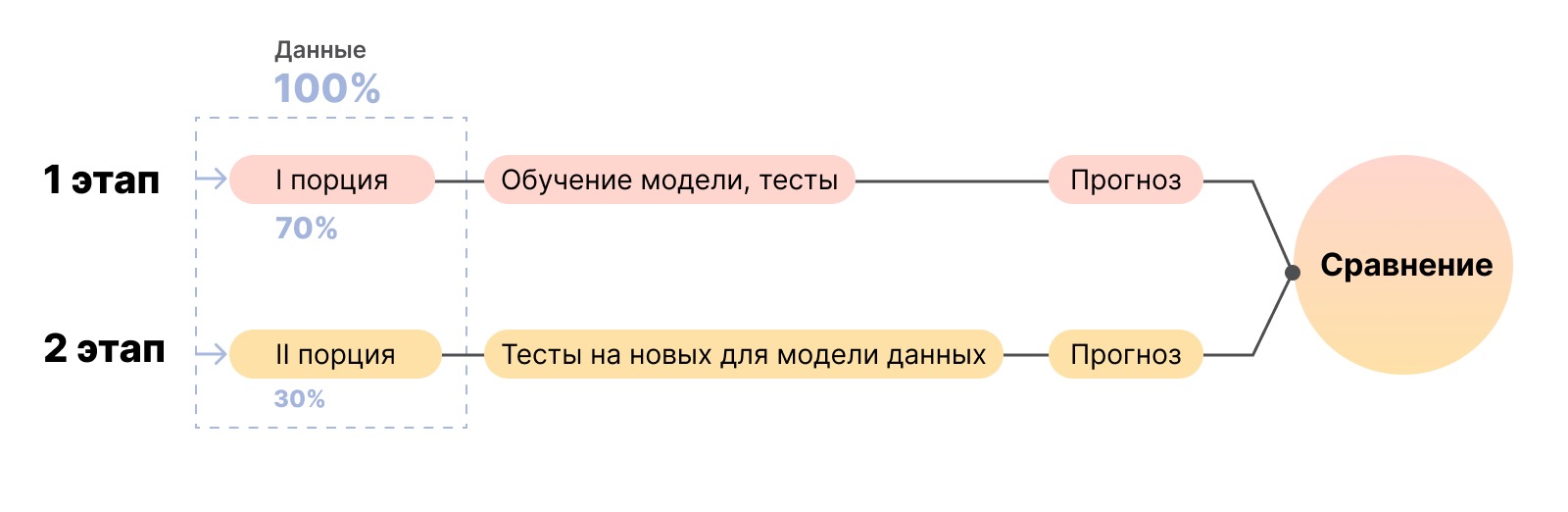
- Тестируем модель: загружаем в нее следующую порцию данных и проверяем, какую вероятность искомого события она предскажет. Часть проверок проводим на новых данных, которые машина еще не видела. Это покажет, совпадают ли результаты тренировочных тестов с реальными результатами.
- Тестирование происходит много раз: это помогает модели самообучаться. Закономерности, которые дали несбывшийся прогноз, удаляем из системы. Данные по удачному прогнозу оставляем. Продолжаем тестировать алгоритм, пока он не научится составлять реалистичные прогнозы.
Приступили к разработке ML-модели и столкнулись с проблемой некачественных данных
Исследовали данные и определили метрики, на которых будем строить модель
Платформа заказчика обрабатывает 500 миллиардов уникальных событий в месяц — для модели машинного обучения этого достаточно. Однако анализ показал, что среди данных много повторяющихся и «мусора». Когда базу очистили, осталось 47 миллионов строк.
Данные распределили по категориям, посчитали количество событий:
- аукционов проведено: 22 746 723;
- аукционов выиграно: 5 390 678;
- показов рекламы: 5 389 276;
- кликов на рекламу: 228 977.
Выбрали, обучили и протестировали модели
С учетом найденных ограничений мы выбрали и протестировали 28 ML-моделей для обучения прогнозированию, например linear regression, CCPM, FNN, PNN. Также взяли мультизадачные модели: shared bottom, ESMM, MMOE и другие.
Модели обучали на данных платформы за 2 месяца. Делили их на порции в соотношении 80/20 или 70/30: порцию побольше использовали для обучения модели, поменьше — для прогнозирования вероятности динамической цены за тысячу показов, кликов, конверсий. Каждый полученный результат заносили в таблицу, сравнивали и анализировали.
Результаты тестов одной из 28 моделей — linear regression
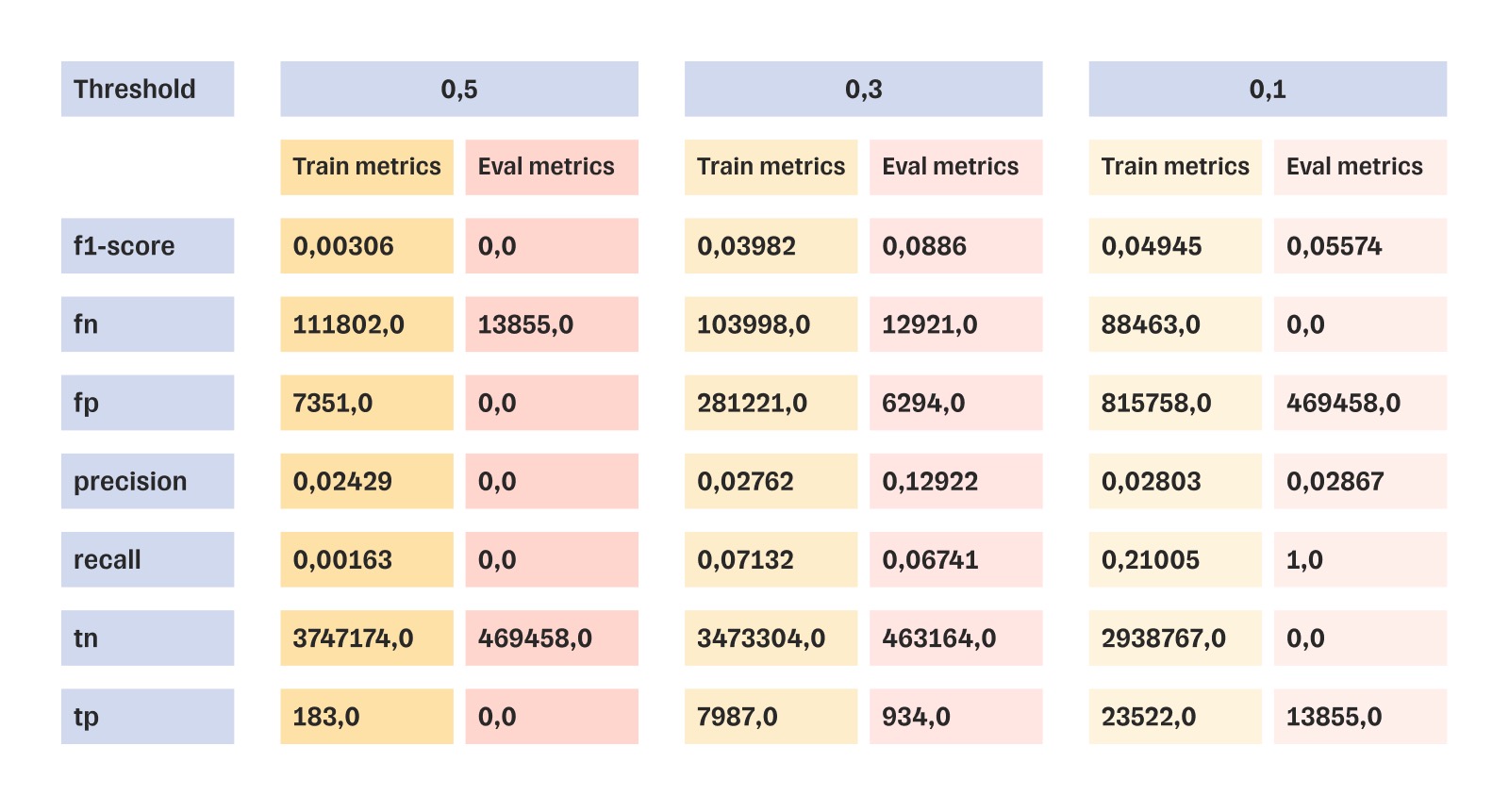
Оценили результаты машинного обучения
Из 28 обученных моделей мы выбрали 5. Самую результативную протестировали дополнительно. Чтобы понимать, подходит ли модель для решения задачи, мы соотносили ее коэффициент f1-score с пороговым значением метрики (threshold).
Если f1-score достигает порогового значения 0,4, то модель даст правильный прогноз с вероятностью 40%. Если коэффициент ниже порогового значения, значит, модель не даст значимого результата.
У самой результативной модели наилучший показатель f1-score составил 0,19. Это вдвое меньше порогового значения. Значит, внедрять эту модель нельзя: прогнозы будут недостоверными.
Результат: остановились на этапе исследования, не потратив деньги на полный цикл разработки и внедрения
Протестировав все подходящие алгоритмы машинного обучения, мы определили, что собранные заказчиком данные не подходили для тренировки. Ни одна из обученных моделей не давала достоверного прогноза.
Мы остановились на этапе предварительного исследования и не стали переходить к внедрению алгоритма Predictor в код рекламной платформы. Таким образом, заказчик проверил свою идею и сэкономил деньги, не вкладываясь в неработающий алгоритм.
Мы предложили заказчику пересобрать систему сбора данных. Мы определим категории и достаточный объем данных для сбора и тогда вернемся к внедрению модели. В этом случае она будет обучена быстрее и прогнозы будут результативными.



Telegram
WhatsApp
+7 499 321-59-32
contact@orbitsoft.com