
Коротко о проекте
-
01
Заказчик
Агрегатор видеороликов, зарабатывает на показах рекламы
-
02
Проблема
У каждого ролика есть несколько изображений для превью, часть из них размытая. Пользователи не открывают такие ролики, не смотрят в них рекламу — компания теряет прибыль
-
03
Решение
Применить методы data science, чтобы найти и удалить все размытые превью: разработать модуль на Python, который отсортирует изображения по качеству
-
04
Результат
- Провели исследование и предложили принцип оценки качества изображений. Согласовали с заказчиком критерии: какие превью считать качественными, какие — нет.
- Написали модуль на Python, который сортирует изображения по степени размытости.
- Модуль проанализировал 50 миллионов изображений: нашел 4,7 миллиона в плохом качестве и 4,5 миллиона в очень хорошем. Остальные — нормального качества.
- Потратили неделю — от ТЗ до результата.
- Заказчик смог удалить с сайта все превью низкого качества и повысить количество просмотров.
Заказчик: агрегатор видеороликов
Компания владеет видеоплатформой, где собраны развлекательные ролики со множества других сайтов. Когда посетитель выбирает видео для просмотра, агрегатор перенаправляет его на сайт владельца контента. Платформа получает вознаграждение, когда пользователи смотрят рекламу на сайтах-источниках.
На платформе размещено более 13 миллионов видео. От владельцев контента компания получает изображения для превью, у каждого ролика их от 1 до 10 штук — всего более 50 миллионов изображений.
Проблема: часть превью-изображений для видео в плохом качестве
Некоторые превью были плохого качества: никакой проверки перед загрузкой платформа не производила. Пользователи не кликали на видео с размытым превью, не смотрели рекламу, а компания теряла прибыль.
Заказчик решил удалить все некачественные изображения, но делать это вручную в таком количестве трудозатратно. Если просматривать каждое изображение хотя бы секунду, потребовалось бы около 14 тысяч часов. Заказчик обратился в OrbitSoft, чтобы автоматизировать процесс.

Решение: написали модуль на Python, который оценивает качество изображений
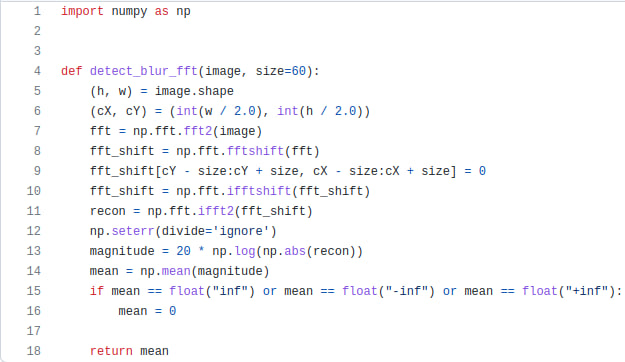
Качественные изображения четкие, некачественные — размытые. Перед нами стояла задача научить алгоритм математически определять степень размытости изображения. Мы начали с изучения профильной литературы по этому вопросу.
Например, в статье Analysis of focus measure operators in shape рассмотрено почти 36 методов вычисления показателя размытости. Мы отметили для себя варианты, которые проще в реализации. Хорошее решение описано в работе Diatom autofocusing in brightfield microscopy: A comparative study. В этом варианте берется один канал изображения и вычисляется абсолютное значение оператора Лапласа. Взяв за основу этот метод, мы написали модуль на Python, который определяет степень размытия изображения.
Другие кейсы обработки big data и обучения искусственного интеллекта из практики OrbitSoft:
Как модуль определяет степень размытия
Каждая картинка состоит из пикселей. Если изображение размытое, на границе объектов получается плавный градиент — цвет соседних пикселей меняется постепенно. Если изображение четкое, то и границы между объектами четкие, а значение цветности соседних пикселей на границе объектов изменяется резко.

Чтобы определить размытость картинки, модуль на Python рассчитывает величину градиента цвета с помощью оператора Лапласа:
1. берет один цветовой канал изображения и сворачивает его с помощью следующего ядра:
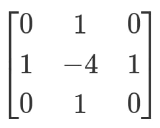
2. рассчитывает дисперсию результата — стандартное отклонение в квадрате;
3. получается коэффициент, по которому можно судить о степени размытия: чем четче изображение, тем больше коэффициент.
Все превью на платформе цветные, а у каждого цвета свой градиент. Когда цветов много, сопоставление занимает много времени. Поэтому мы решили переводить изображения в черно-белый монохром. Так алгоритму придется рассчитывать только градации серого. Качество оценки изображения это не снижает, зато сокращает время обучения математической модели.
Как модуль переводит изображения в монохром

Чтобы переводить цветные изображения в черно-белые, нужно было подключить библиотеку, которая умеет работать с цветом. Мы протестировали несколько Python-библиотек и остановились на OpenCV.
OpenCV — это библиотека компьютерного зрения, с помощью которой можно обрабатывать, анализировать и классифицировать изображения. Она поддерживает все популярные форматы файлов и хорошо работает с разрешением изображений — то, что было нужно для нашей задачи.
Как модуль оценивает качество изображения
Результат работы алгоритма — коэффициент, который принимает значения от 0 до 2000. Чем его значение выше, тем изображение качественнее.
Важным моментом было определить пороговое значение этого коэффициента: какие изображения считать достаточно четкими, а какие — уже размытыми. Мы согласовали с заказчиком, что качественными будем считать превью с коэффициентом больше 100.
Результат: модуль нашел 4,7 миллиона изображений в плохом качестве и 4,5 миллиона в отличном
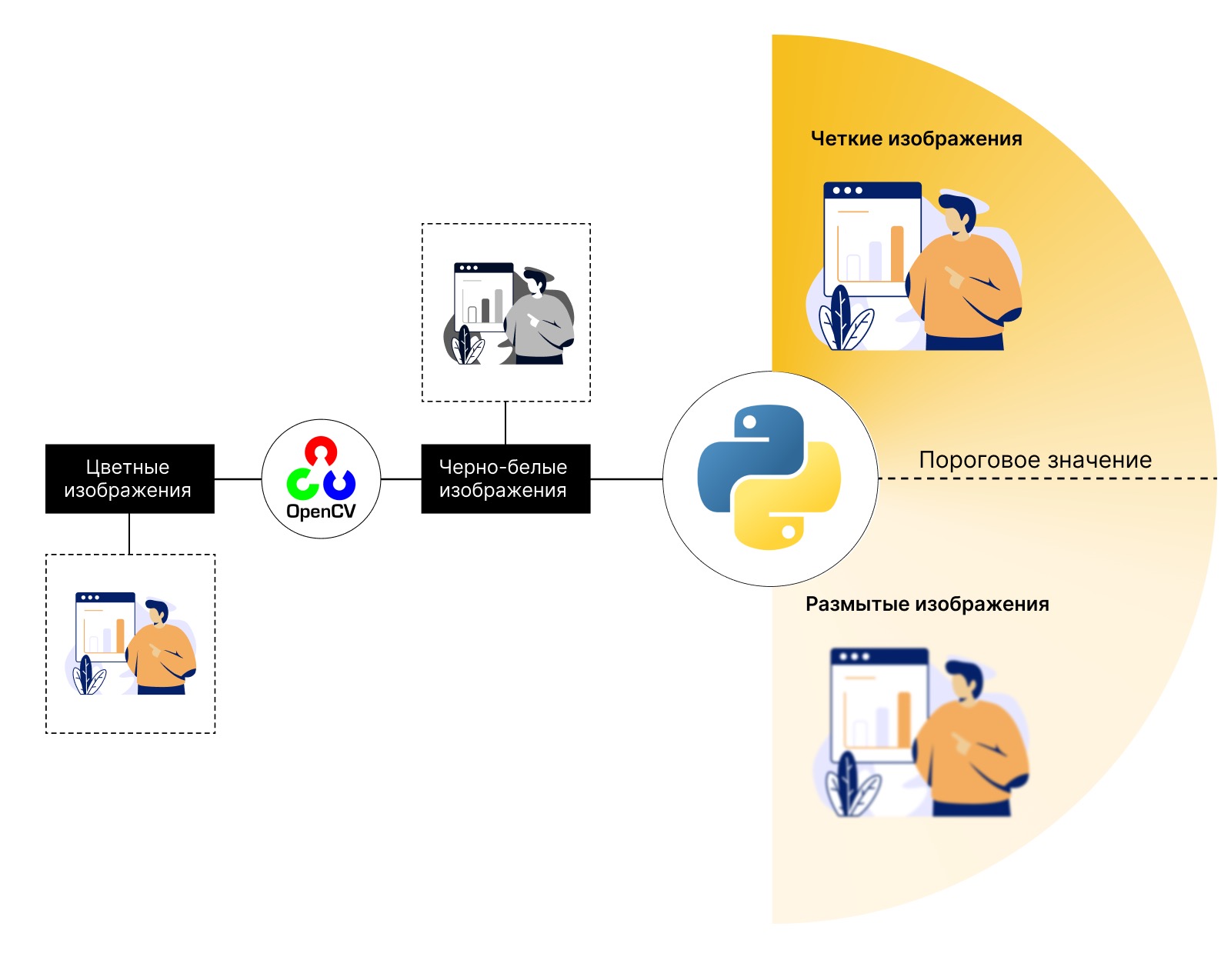
1. переводит загруженные на платформу превью в монохром;
2. рассчитывает коэффициент размытия;
3. распределяет изображения по двум группам: если коэффициент ниже порогового значения, изображение размытое, если выше — четкое.
Методы data science позволили нам автоматизировать оценку качества изображений. Вручную на это понадобилось бы более 14 тысяч рабочих часов. У нас ушло меньше 40: от постановки задачи до результата.
Модуль на Python проанализировал 50 миллионов изображений и распределил их по двум группам:
- 4,7 миллиона изображений размытые: коэффициент от 0 до 100;
- остальные — достаточно четкие, из них 4,5 миллиона очень хорошего качества: коэффициент больше 1000.
Со временем заказчик убрал с сайта все изображения в плохом качестве. Количество просмотров на платформе возросло.



Telegram
WhatsApp
+7 499 321-59-32
contact@orbitsoft.com