
Если бизнес зарабатывает в интернете, он всегда каким-то образом собирает и анализирует данные, например, какие карточки товаров пользователи изучают, а какие пропускают. Или какое видео, кто и когда и смотрит и с какого устройства. Такие данные нужны, чтобы понимать, как развивать свой продукт.
Чем больше данных, тем сложнее их обрабатывать, поэтому нужны высоконагруженные системы. На примере своей разработки рассказываем, как проектируем такие решения. За апрель наша система обработала 2,4 млрд показов и 408 млн кликов, и все обошлось без сбоев.
Задача бизнеса — повысить конверсию с показа контента
Один из способов заработать для интернет-бизнеса — управлять контентом так, чтобы пользователи как можно чаще совершали целевые действия. Контент в этом случае — общее обозначение, это могут быть:
- ролики,
- новости,
- карточки товаров или услуг
- и что угодно еще.
Что будет целевым действием, тоже зависит от бизнеса. В одном случае — просмотр энного количества роликов, в другом — подписка на пробные уроки из рассылки.
Для управления контентом нужны данные, о том, как именно пользователь работает с контентом. Может, он пропускает карточки товаров с наибольшей маржинальностью для компании или все-таки изучает, но не откладывает в корзину. Все это нужно, чтобы понять — как и что показывать пользователю.
Сам по себе массив данных мало что дает, поэтому его надо как-то сохранять и анализировать. Например,
- собирать статистические отчеты по срезам и метрикам,
- сравнивать эти же метрики за разные периоды,
- группировать данные по категориям — странам, городам, типам устройств или времени суток.
Без таких деталей сложно определить, почему какой-то контент срабатывает не так, как запланировали и что делать для решения проблемы.
Когда данных немного, их можно обратывать вручную или с помощью простых программ. Но с ростом базы пользователей, объем данных тоже увеличивается, поэтому обработать условный миллиард данных таким способом уже не получится.
Для этого обработки большого массива проектируют системы сбора и анализа данных. Основное требование для них — выдерживать высокую нагрузку.
Опыт OrbitSoft: как устроена система сбора и анализа данных
У нас есть опыт в запуске систем, которые справляются с высокой нагрузкой. Поэтому на примере одного из проекта покажем свой подход к разработке.
О проекте. Каждый день рекламная сеть регистрирует события — ставки, которые делают пользователи на аукционах, просмотры рекламы, клики по объявлениям. Чтобы аналитики могли работать с данными, их нужно привести в читаемый формат: обработать и загрузить в программу с понятным интерфейсом.
Нагрузка системы. В апреле 2021 года система рекламной сети обработала:
- 2,4 млрд показов
- 408 млн кликов
- 1240 конверсий
Анализ. Чтобы спроектировать систему, мы изучили тип и объем данных, прогнозируемый рост нагрузки, результат, который нужно получить и ограничения по бюджету и ресурсам. После этого приступили уже к самой разработке.
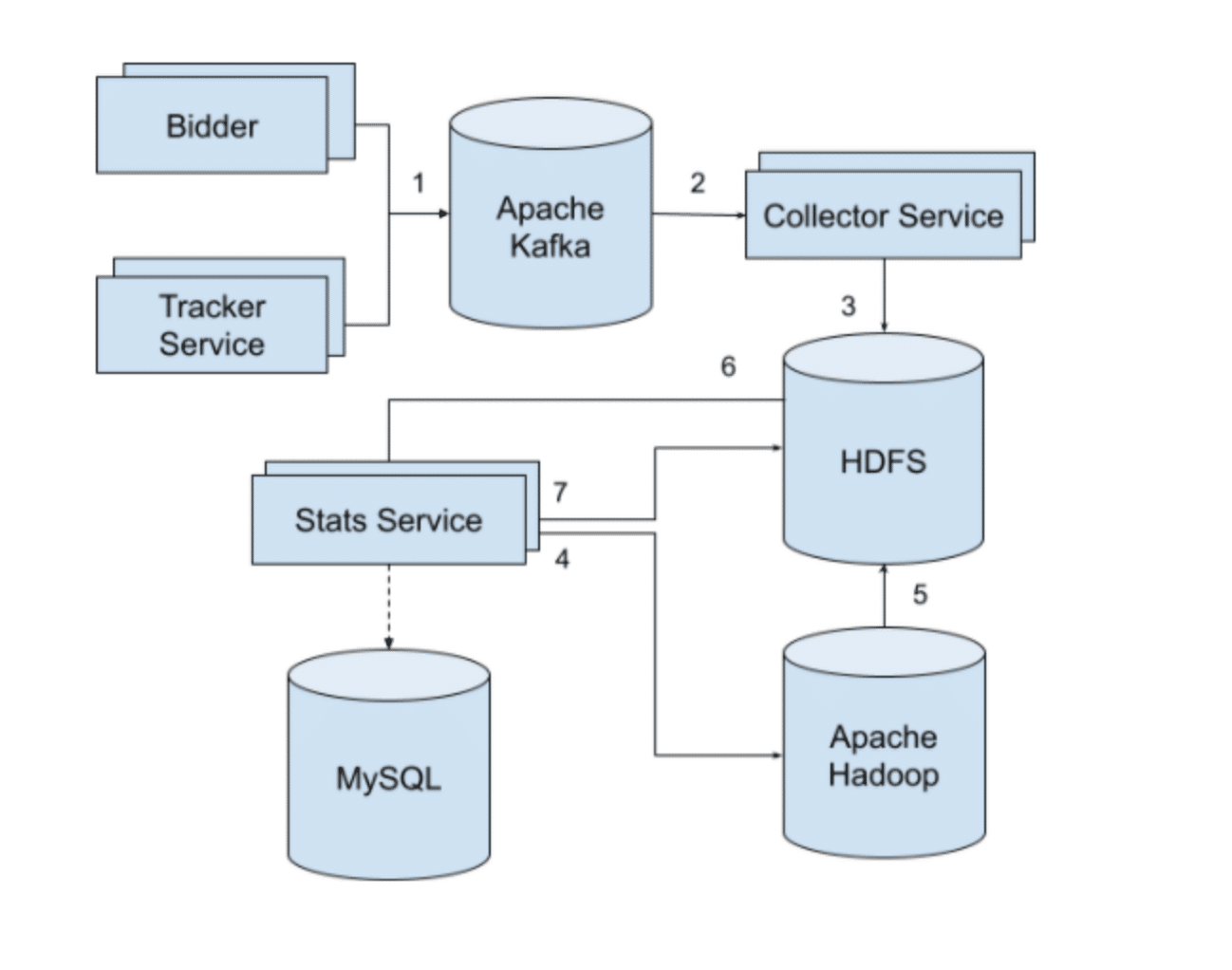
Схема работы системы:
- Рекламная платформа регистрирует события в Apache Kafka
- Collector Service следит за очередью событий в Apache Kafka, обогащает информацию о событии дополнительными данными и записывает информацию о событиях в *.csv файлы.
- После завершения записи в файл Collector Service сжимает его и загружает этот файл в HDFS, в специальную директорию для входных данных.
- Каждые 5 минут Stats Service проверяет наличие новых необработанных файлов в директории входных данных на HDSF и формирует задачу для Apache Hadoop для расчета агрегированной статистики.
- Apache Hadoop рассчитывает статистику на основании входных данных и записывает полученные результаты в файлы в специальную директорию на HDFS.
- Stats Server забирает результаты расчета статистики с HDFS и экспортирует данные в MySQL.
- Stats Server перемещает обработанные входные файлы в архив расположенный также на HDFS. Файлы группируются по дням — это нужно для того, чтобы можно было пересчитать статистику за определенный период времени, если были какие-то ошибки в скриптах.
Результаты. Все компоненты архитектуры горизонтально масштабируются и обеспечивают отказоустойчивость.
| Компонент | Что дает |
| Распределенный брокер сообщений Apache Kafka | Обрабатывает до несколько сотен тысяч событий в секунду; Сообщения будут доходить, даже если один из серверов выйдет из строя; Адаптируется под рост нагрузки — легко добавить новые серверы. |
| Демон Collector Service на Go | Обрабатывает десятки тысяч сообщений в секунду; Адаптируется под рост нагрузки — может запускать несколько экземпляров сервиса параллельно и распределять между ними работу. |
| Распределенная файловая система Hadoop Distributed File System | Безопасно хранит данные Отдает те данные, о которых попросили Записывает то, что ей прислали. Благодаря репликации блоков по узлам данных, они не потеряются |
| Демон Stats Server на Java | Быстрая скорость вычислений благодаря модели вычислений Map Reduce: массив данных разделяется на части, каждая часть параллельно обрабатывается и соединяется воедино. |
Эксперты ответят на ваш вопрос
Эксперты Orbitsoft отвечают на вопросы разработчиков, владельцев и управляющих бизнесом. Спрашивайте, все что болит или просто интересно.
Чтобы мы разобрали вашу ситуацию или поделились опытом, пишите на Anna.mandrikina@orbitsoft.com



Telegram
WhatsApp
+7 499 321-59-32
contact@orbitsoft.com